Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门
YouTube教程
Python Web Scraping Signature Series Tutorial 1 : Get Request with Python, Google Translate Part 1
检测---network---第二个single?client=。。。。。 ---preview可见 翻译结果

name:第二个文件single?client=....
headers
request url:
http://translate.google.cn/translate_a/single?client=t&sl=en&tl=zh-CN&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&source=btn&srcrom=1&ssel=3&tsel=6&kc=0&tk=749722.875867&q=signature

复制这个链接,打开新的网页会下载一个txt
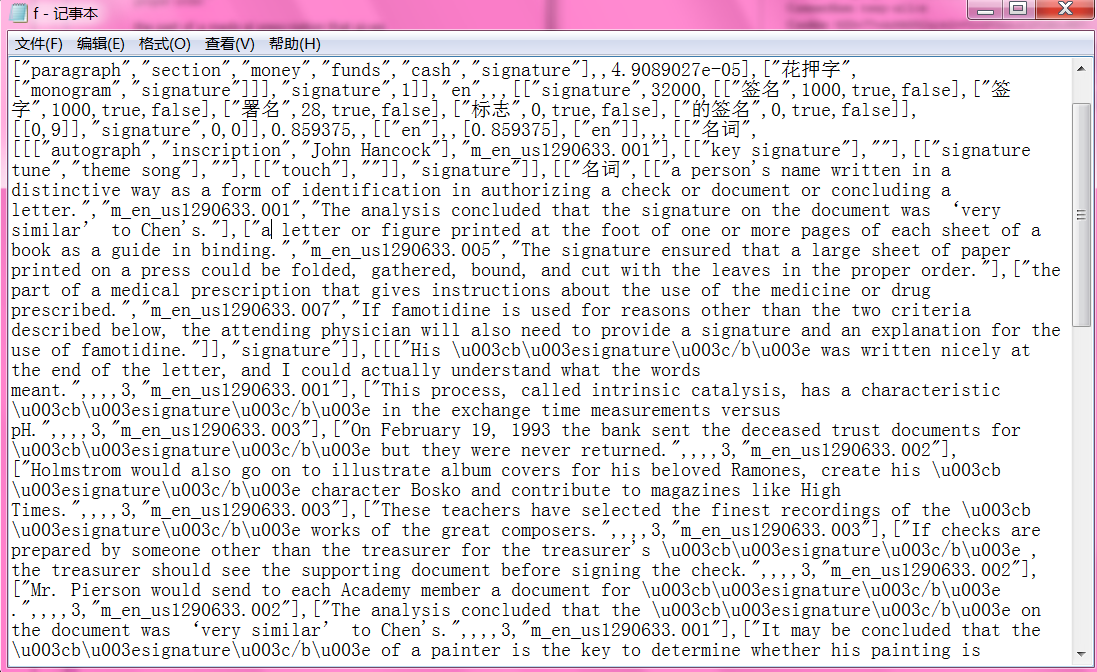
其内容是对具体的翻译解释

出现urllib2.HTTPError: HTTP Error 403: Forbidden错误是由于网站禁止爬虫,可以在请求加上头信息,伪装成浏览器访问 #伪装浏览器头 headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'} req = urllib2.Request(url = ' = headers) feeddata = urllib2.urlopen(req).read() #或者 #opener = urllib2.build_opener() #feeddata = opener.open(request).read() print feeddata.decode('u8')